This was the midterm project of the course Big Data and Business Analytics.
For this project, our goal is to predict future stock trend (up, down or neutral) based on news on companies.
It would be really helpful while making decisions of investing.
Advisor: Prof. Li-wei Yang @NTUIM
Co-workers:
Judy Liu, Kai-Ming Shan @NTUIM ;
Tsai-Tin Yu, Pei-shuan Lee, Shin-Rou Huang, Jin-Yi Ho @NTUIB

Due to authority and IP policies, only few slides and contents are shown below.
Data Description
Data Source: Professor.
- csv file of stock prices of Taiwan company in a month.
- news in a month (in chinese)
We used news and prices from three companies: A, B, and C.
Further, we define the classes and labelled each news based on following rules:
- NODATA: If no price data (basically ignore)
- COMMON: abs(Price(Today+7)-Price(Today))/Price(Today)<=0.05
- GOUP: Price(Today+7) > Price(Today) if not COMMON
- GODOWN: Price(Today+7) < Price(Today) if not COMMON

Data Preprocessing
We used two-gram partitioning on news to generate keywords.
To be mention, since the text is in Chinese, we will merge the words to N-gram if possible.
For instance, A: 你 好+ B: 好 嗎 -> 你好嗎
Which the bold 好 is a shared word in A’s tail and B’s head.
After getting the keywords, we define:
- GOUP keywords: keyword from GOUP news, which are features indicating stock price increases
- GODOWN keywords: keyword from GODOWN news, which are features indicating stock price decreases

Algorithms
We implemented KNN model for this problem:
First, we need to construct the feature vectors for news and the vector space.
Basically, we tried three methods of creating vectors:
- 0/1 method: word appears in text=1, else 0
- tf method: word frequency in text
- tf-idf value: tf-idf value of the word
 Therefore, we have a dim(GOUP)+dim(GODOWN) dimension vector space.
Therefore, we have a dim(GOUP)+dim(GODOWN) dimension vector space.
As for the distance function of kNN, which is Euclidean Distance.

Last, since we have three classes, we might encounter some problems while setting k=3.
Thus, we find the four points which have minimum distances.
After then, we tried to use majority voting of first three points to predict the value.
If those three classes have the same vote (=1), we use the fourth neighbor’s value as prediction.

Result
We did inside test to test the accuracy.
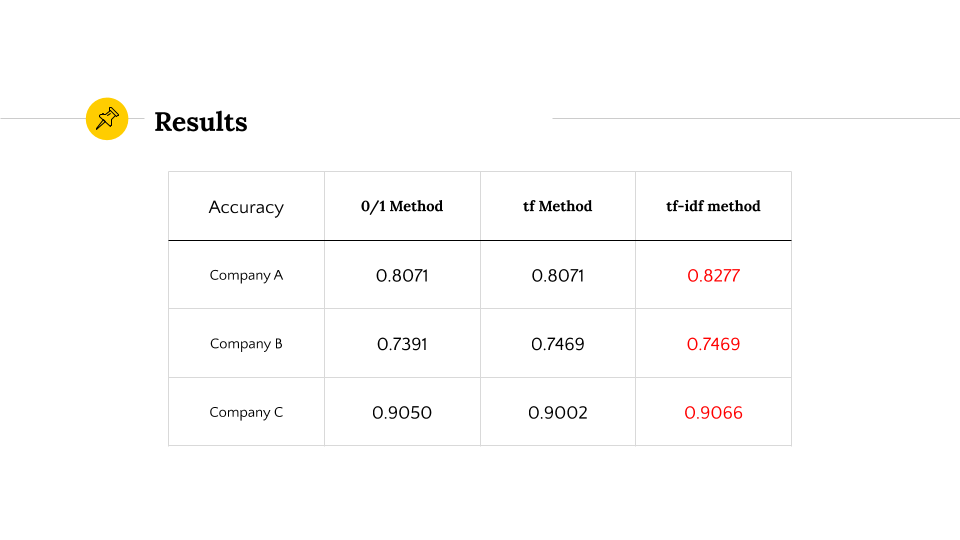
As a result, we got the best accuracy of:
- A company: 0.8277
- B company: 0.7469
- C company: 0.9066
all with the tf-idf vector generation method.